背景信息
内容简介
在大模型时代,随着模型效果的显著提升,模型评测的重要性日益凸显。科学、高效的模型评测,不仅能帮助开发者有效地衡量和对比不同模型的性能,更能指导他们进行精准地模型选择和优化,加速AI创新和应用落地。因此,建立一套平台化的大模型评测最佳实践愈发重要。
本文为PAI大模型评测最佳实践,旨在指引AI开发人员使用PAI平台进行大模型评测。借助本最佳实践,您可以轻松构建出既能反映模型真实性能,又能满足行业特定需求的评测过程,助力您在人工智能赛道上取得更好的成绩。最佳实践包括如下内容:
• 如何准备和选择评测数据集
• 如何选择适合业务的开源或微调后模型
• 如何创建评测任务并选择合适的评价指标
• 如何在单任务或多任务场景下解读评测结果
平台亮点
PAI大模型评测平台,适合您针对不同的大模型评测场景,进行模型效果对比。例如:
• 不同基础模型对比:Qwen2-7B-Instruct vs. Baichuan2-7B-Chat
• 同一模型不同微调版本对比:Qwen2-7B-Instruct 在私有领域数据下训练不同 epoch 版本效果对比
• 同一模型不同量化版本对比:Qwen2-7B-Instruct-GPTQ-Int4 vs. Qwen2-7B-Instruct-GPTQ-Int8
考虑到不同开发群体的特定需求,我们将以企业开发者与算法研究人员两个典型群体为例,探讨如何结合常用的公开数据集(如MMLU、C-eval等)与企业的自定义数据集,实现更全面准确并具有针对性的模型评测,查找适合您业务需求的大模型。最佳实践的亮点如下:
• 端到端完整评测链路,无需代码开发,支持主流开源大模型,与大模型微调后的一键评测;
• 支持用户自定义数据集上传,内置10+通用NLP评测指标,一览式结果展示,无需再开发评测脚本;
• 支持多个领域的常用公开数据集评测,完整还原官方评测方法,雷达图全景展示,省去逐个下载评测集和熟悉评测流程的繁杂;
• 支持多模型多任务同时评测,评测结果图表式对比展示,辅以单条评测结果详情,方便全方位比较分析;
• 评测过程公开透明,结果可复现。评测代码开源在与ModelScope共建的开源代码库eval-scope中,方便细节查看与复现:
https://github.com/modelscope/eval-scope
前提条件
• 已开通PAI并创建了默认工作空间。具体操作,请参见开通PAI并创建默认工作空间。
• 如果选择自定义数据集评测,需要创建OSS Bucket存储空间,用来存放数据集文件。具体操作,请参见控制台创建存储空间。
使用费用
• PAI大模型评测依托于PAI-快速开始产品。快速开始是PAI产品组件,集成了众多AI开源社区中优质的预训练模型,并且基于开源模型支持零代码实现从训练到部署再到推理的全部过程,给您带来更快、更高效、更便捷的AI应用体验。
• 快速开始本身不收费,但使用快速开始进行模型评测时,可能产生DLC评测任务费用,计费详情请参见DLC计费说明。
• 如果选择自定义数据集评测,使用OSS存储,会产生相关费用,计费详情请参见OSS计费概述。
场景一:面向企业开发者的自定义数据集评测
企业通常会积累丰富的私有领域数据。如何充分利用好这部分数据,是企业使用大模型进行算法优化的关键。因此,企业开发者在评测开源或微调后的大模型时,往往会基于私有领域下积累的自定义数据集,以便于更好地了解大模型在私有领域的效果。
对于自定义数据集评测,我们使用NLP领域标准的文本匹配方式,计算模型输出结果和真实结果的匹配度,值越大,模型越好。使用该评测方式,基于自己场景的独特数据,可以评测所选模型是否适合自己的场景。
以下将重点展示使用过程中的一些关键点,更详细的操作细节,请参见模型评测产品文档。
1. 准备自定义评测集
1.1. 自定义评测集格式
1. 基于自定义数据集进行评测,需要提供JSONL格式的评测集文件
o 文件格式:使用question标识问题列,answer标识答案列。
o 文件示例:llmuses_general_qa_test.jsonl

2. 符合格式要求的评测集,可自行上传至OSS,并创建自定义数据集,详情参见上传OSS文件和创建及管理数据集。
1.2. 创建自定义评测集
1. 登录PAI控制台。
2. 在左侧导航栏选择AI资产管理>数据集,进入数据集页面
3. 单击创建数据集
4. 填写创建数据集相关表单,从OSS中选择您的自定义评测集文件
2. 选择适合业务的模型
2.1. 查找开源模型
1. 在PAI控制台左侧导航栏选择快速开始,进入快速开始页面
2. 单击快速开始提供的模型分类信息,直接进入到模型列表中,根据模型描述信息进行查看。
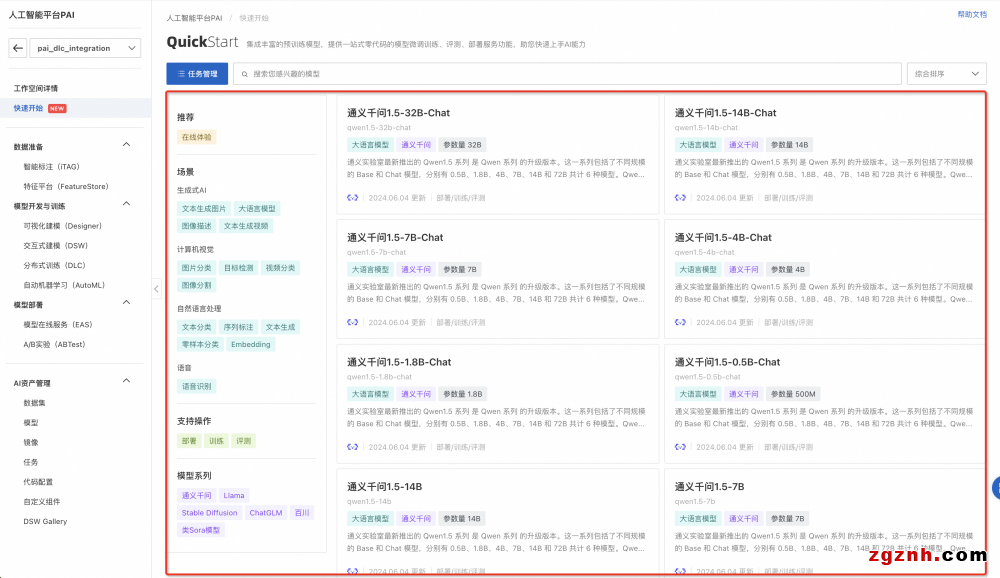
3. 单击进入模型详情页后,对于可评测的模型,会展示评测按钮。
a. 支持模型类型:当前模型评测支持HuggingFace所有AutoModelForCausalLM类型的模型
2.2. 使用微调后的模型
1. 使用快速开始进行模型微调,详细步骤请参见模型部署及训练
2. 微调完成后,在快速开始>任务管理>训练任务中,单击训练好的任务名称,进入任务详情页后,对于可评测的模型,右上角会展示评测按钮。
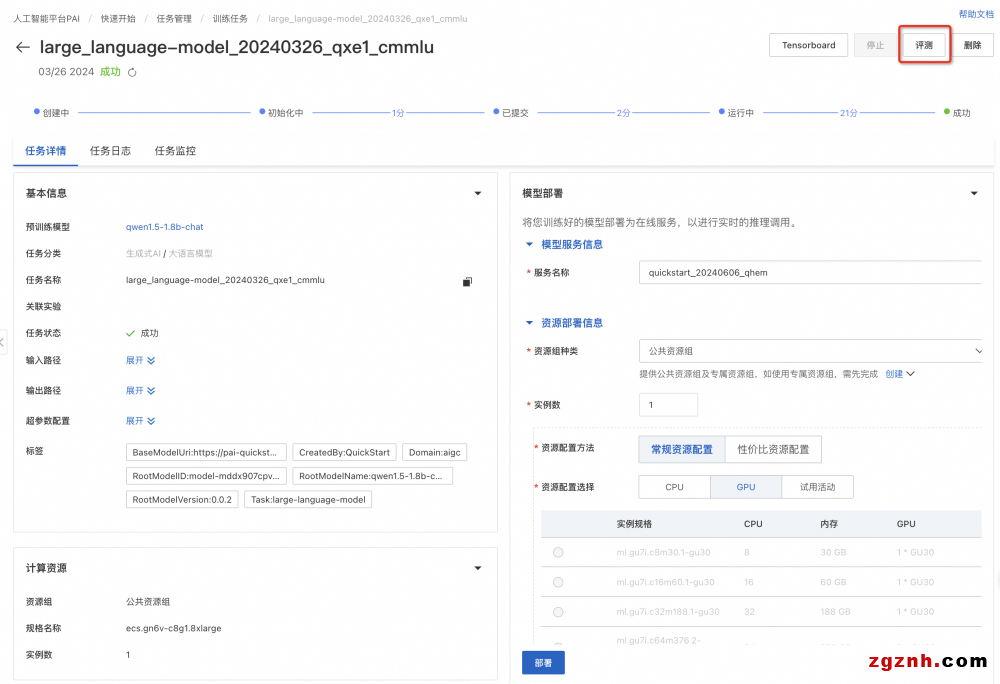
3. 创建评测任务
1. 在模型详情页右上角单击评测,创建评测任务
2. 在新建评测任务页面,配置以下关键参数。

3. 任务创建成功后,将自动分配资源,并开始运行。
4. 运行完成后,任务状态显示为已成功。
4. 查看评测结果
4.1. 评测任务列表
1. 在快速开始页面,单击搜索框左侧的任务管理。
2. 在任务管理页面,选择模型评测标签页。
4.2. 单任务结果
1. 在模型评测列表页,单击评测任务的查看报告选项,即可进入评测任务详情页
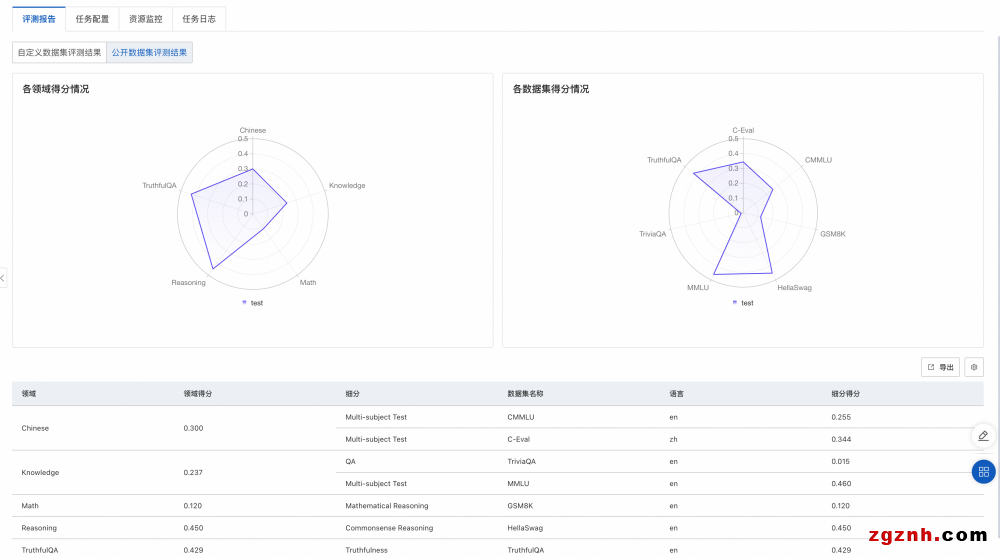
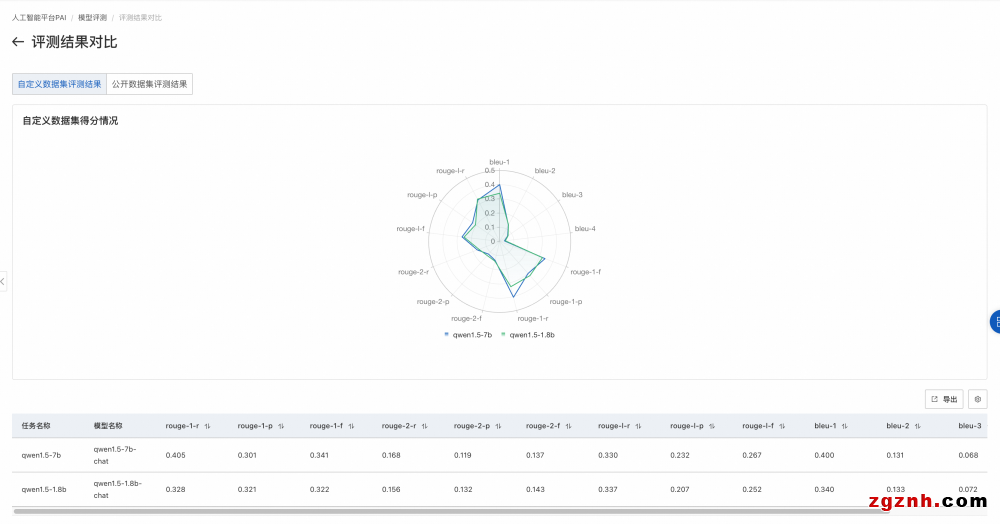
2. 评测报告如下图所示,选择自定义数据集评测结果,将在雷达图展示该模型在ROUGE和BLEU系列指标上的得分。此外还会展示评测文件每条数据的评测详情。

• rouge-n类指标计算N-gram(连续的N个词)的重叠度,其中rouge-1和rouge-2是最常用的,分别对应unigram和bigram,rouge-l 指标基于最长公共子序列(LCS)。
• bleu (Bilingual evaluation Understudy) 是另一种流行的评估机器翻译质量的指标,它通过测量机器翻译输出与一组参考翻译之间的N-gram重叠度来评分。其中bleu-n指标计算n-gram的匹配度。
3. 最终评测结果会保存到您指定的OSS路径中
4.3. 多任务对比
1. 当需要对比多个模型的评测结果时,可以将它们聚合在一个页面上展示,以便于比较效果。
2. 具体操作为在模型评测任务列表页,左侧选择想要对比的模型评测任务,右上角单击对比,进入对比页面。
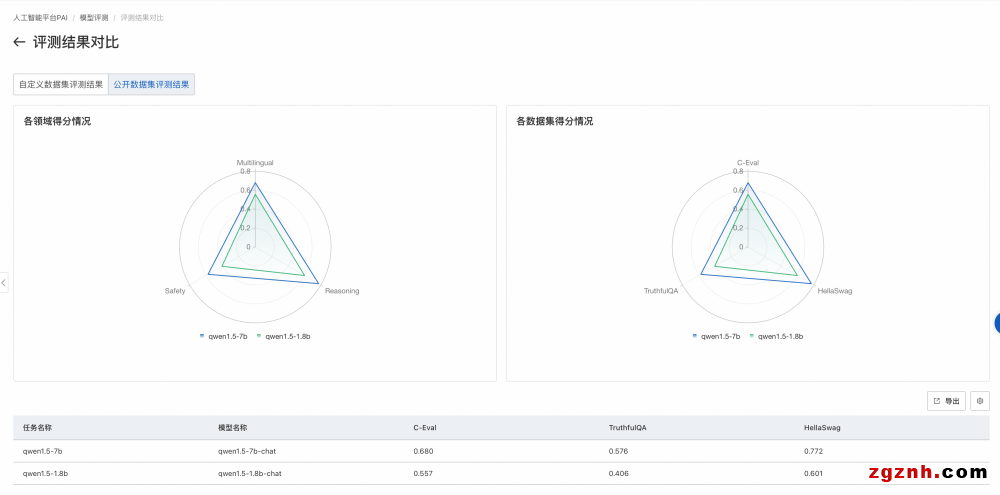
3. 自定义数据集评测对比结果
场景二:面向算法研究人员的公开数据集评测
算法研究通常建立在公开数据集上。研究人员在选择开源模型,或对模型进行微调后,都会参考其在权威公开数据集上的评测效果。然而,大模型时代的公开数据集种类繁多,研究人员需要花费大量时间调研选择适合自己领域的公开数据集,并熟悉每个数据集的评测流程。为方便算法研究人员,PAI接入了多个领域的公开数据集,并完整还原了各个数据集官方指定的评测metrics,以便获取最准确的评测效果反馈,助力更高效的大模型研究。
在公开数据集评测中,我们通过对开源的评测数据集按领域分类,对大模型进行综合能力评估,例如数学能力、知识能力、推理能力等,值越大,模型越好,这种评测方式也是大模型领域最常见的评测方式。
以下将重点展示使用过程中的一些关键点,更详细的操作细节,请参见模型评测产品文档。
1. 支持的公开数据集
目前PAI维护的公开数据集包括MMLU、TriviaQA、HellaSwag、GSM8K、C-eval、CMMLU、TruthfulQA,其他公开数据集陆续接中。

2. 选择适合的模型
2.1. 查找开源模型
1. 在PAI控制台左侧导航栏选择快速开始,进入快速开始页面
单击快速开始提供的模型分类信息,直接进入到模型列表中,根据模型描述信息进行查看。
3. 单击进入模型详情页后,对于可评测的模型,会展示评测按钮。
a. 支持模型类型:当前模型评测支持HuggingFace所有AutoModelForCausalLM类型的模型
2.2. 使用微调后的模型
1. 使用快速开始进行模型微调,详细步骤请参见模型部署及训练
2. 微调完成后,在快速开始>任务管理>训练任务中,单击训练好的任务名称,进入任务详情页后,对于可评测的模型,右上角会展示评测按钮。
3. 创建评测任务
1. 在模型详情页右上角单击评测,创建评测任务
2. 在新建评测任务页面,配置以下关键参数。本文以MMLU数据集为例。

3. 任务创建成功后,将自动分配资源,并开始运行。
4. 运行完成后,任务状态显示为已成功。
4. 查看评测结果
4.1. 评测任务列表
1. 在快速开始页面,单击搜索框左侧的任务管理。
2. 在任务管理页面,选择模型评测标签页。
4.2. 单任务结果
1. 在模型评测列表页,单击评测任务的查看报告选项,即可进入评测任务详情页
2. 评测报告如下图所示,选择公开数据集评测结果,将在雷达图展示该模型在公开数据集上的得分。
o 左侧图片展示了模型在不同领域的得分情况。每个领域可能会有多个与之相关的数据集,对属于同一领域的数据集,我们会把模型在这些数据集上的评测得分取均值,作为领域得分。
o 右侧图片展示模型在各个公开数据集的得分情况。每个公开数据集的评测范围详见该数据集官方介绍。
3. 最终评测结果会保存到您指定的OSS路径中
4.3. 多任务对比
1. 当需要对比多个模型的评测结果时,可以将它们在聚合在一个页面上展示,以便于比较效果。
2. 具体操作为在模型评测任务列表页,左侧选择想要对比的模型评测任务,右上角单击对比,进入对比页面。
3. 公开数据集评测对比结果